Synthetic Data, Better Than Real
Synthetic data should not ruin models, it should improve them. Ours does.
Train on synthetic, outperform real. On 23 public data sets Roll Data wins against the original data 78% of the time, ties the rest.
Maximum model performance, maximum privacy, or somewhere in between. You decide.
No data set will ever be too small or too sensitive for AI.
Utility or Privacy? Why not both? A new Pareto frontier for synthetic data.
LightGBM model utility vs. privacy (P5 NNDR) for Roll Data across 23 datasets and four privacy levels, compared to CTGAN, TVAE, and Gaussian Copula.
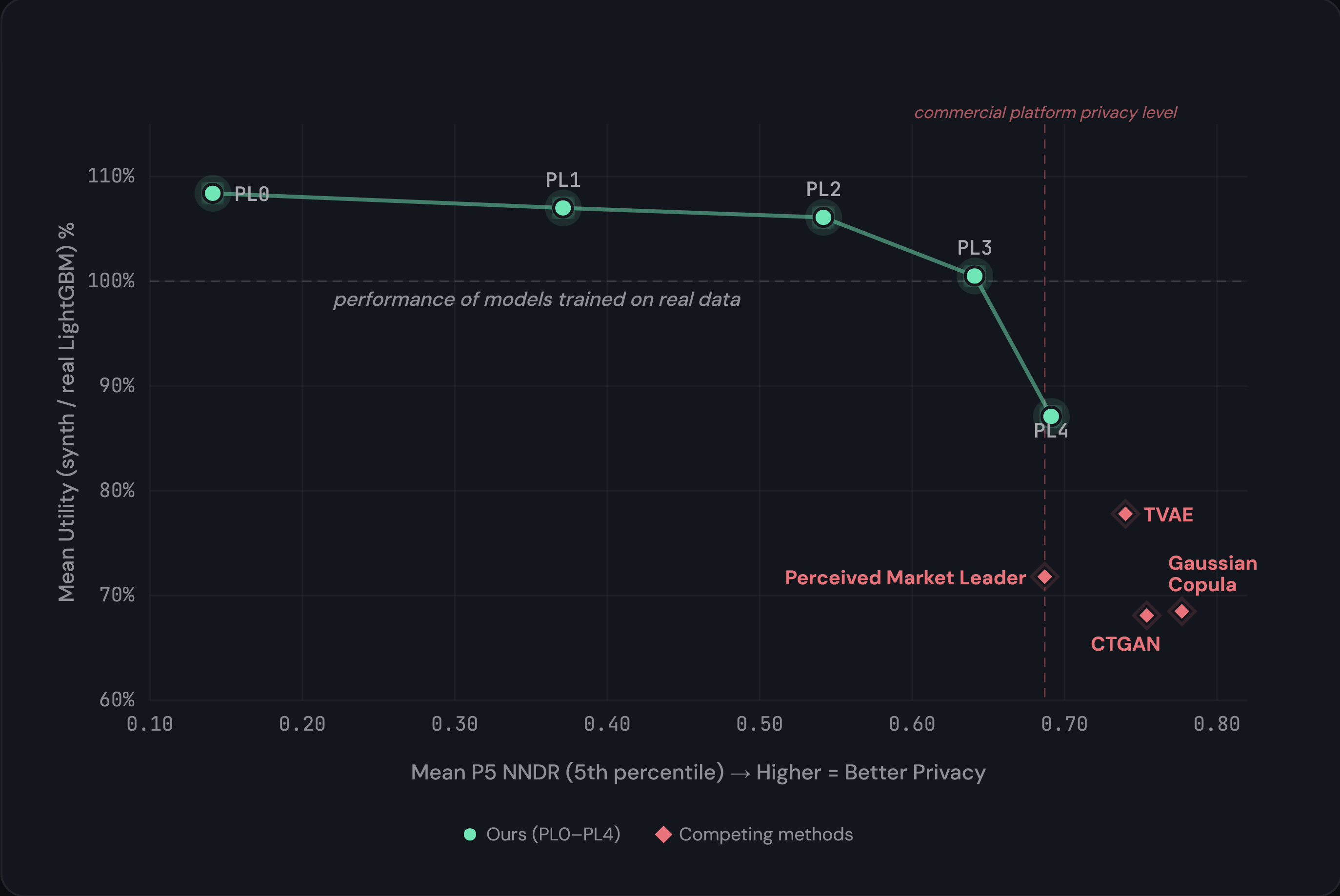
The industry is stuck in low utility. We've created a new frontier.
Extraordinary claims require extraordinary evidence. Here's our evidence.
Download well known open data sets, Roll Data that was synthesized from them, and notebooks to explore it. All synthesis was performed on an 8 vCPU VM. Roll Data runs anywhere. A CPU VM handles it. A GPU makes it fly.
Let's Roll →Want to synthesize your own data? Try our data synthesizer here.
Roll My Own →Ready to Roll? Get in touch for a demo with ryan@rolldata.ai